- Робота з повнотекстовим пошуком (FTS)
- Загальна інформація
- Увімкнення FTS для додатка
- Використання та налаштування токенізатора в повнотекстовому пошуку
- Додавання сутностей до повнотекстового пошуку
- Початкове побудова повнотекстового індексу / переіндексація
- Налаштування асинхронної реіндексації
- Програмне використання повнотекстового пошуку
- UI-елементи повнотекстового пошуку
- Правила побудови запитів
Робота з повнотекстовим пошуком (FTS) #
Загальна інформація #
У платформу UnityBase вбудовано сервіс повнотекстового пошуку на базі розширення SQLite FTS3,
з підтримкою української, російської та англійської морфології (токенізатор stemka).
Починаючи з версії UB@5.25.26 підтримуються також розширення SQLite FTS5 з токенізаторами unicode61, porter та trigram.
Сервіс може бути використаний як в «ручному» (програміст самостійно повинен написати CRUID операції для оновлення повнотекстового індексу при зміні даних сутності), так і в «автоматичному» режимі - в цьому випадку для сутностей, які необхідно індексувати повнотекстовим пошуком, необхідно увімкнути та налаштувати міксин `fts.
При роботі через міксин оновлення повнотекстового індексу проводиться «на льоту», тобто відразу ж після оновлення даних
сутності (після коміту транзакцій), або в «асинхронному» режимі (application.fts.async=true в конфігурації додатка).
Існує можливість як використовувати загальний індекс для декількох сутностей, так і рознести сутності по різних
БД повнотекстового пошуку (вказанням різних mixins.fts.connectionName в метафайлах сутності).
Підтримується пошук з обмеженнями за ДАТОЮ і за списками контролю доступу (mixin aclRLS).
Увімкнення FTS для додатка #
Нижче наведено приклади для додатка autotest
Увімкнемо FTS на рівні додатка, додавши в конфіг (ubConfig.json) опцію fts.enabled: true:
"application": {
......
"fts": {
"enabled": true
},
}
Додаємо коннекшин для SQLite БД повнотекстового пошуку. Ім'я з'єднання за замовчуванням ftsDefault:
"application": {
......
"fts": {
"enabled": true,
},
.....
"connections": [{
"name": "ftsDefault",
"driver": "SQLite3",
"dialect": "SQLite3",
"databaseName": "./fts/autotestFTS.ftsdb",
"supportLang": ["uk"],
"advSettings": "Synchronous=Off,Tokenizer=stemka,TokenizerParams=\"stem=yes\""
},
......
]
}
При необхідності можна визначити кілька повнотекстових БД (конекшинів), при цьому в описі міксинів сутності необхідно вказувати імена відповідних з'єднань.
Приклад додавання другого конекшену:
"application": {
......
"fts": {
"enabled": true,
},
.....
"connections": [{
"name": "ftsDefault",
"driver": "SQLite3",
"dialect": "SQLite3",
"databaseName": "./fts/autotestFTS.ftsdb",
"supportLang": ["uk"],
"advSettings": "Synchronous=Off,Tokenizer=stemka,TokenizerParams=\"stem=yes\""
}, {
"name": "ftsSubjectSearch",
"driver": "SQLite3",
"dialect": "SQLite3",
"databaseName": "./fts/autotestFTSSubjectSearch.ftsdb",
"supportLang": ["uk"],
"advSettings": "Synchronous=Off,Tokenizer=stemka,TokenizerParams=\"stem=yes\""
},
.....
]
}
У міксині сутності відповідне з'єднання другого конекшену явно вказуємо через «connectionName»: «ftsSubjectSearch»
**Важливо: **
- БД повнотексту повинні розташовуватися на локальній до сервера додатків файловій системі (бажано SSD)
- Рекомендується називати файл БД, починаючи з імені додатка
- обов'язково необхідно задати список підтримуваних мов
- директорія, в якій знаходиться БД, повинна існувати. На етапі додавання FTS БД повинна бути відсутня
- SQLIte база переключена в режим WAL. BusyTimeout=10sec. Не робіть довгих транзакцій
- параметр «advSettings»: «Synchronous=Off» в 20 разів прискорює зміни в повнотекстовий індекс, але при цьому ваш сервер повинен бути захищений від перепадів живлення
Використання та налаштування токенізатора в повнотекстовому пошуку #
Токенізатор — це програма, яка розбиває рядки на лексеми.
Платформа UnityBase підтримує токенізатор «stemka», який може не тільки коректно розбивати рядки на українські та російські лексеми, а також містить у собі імовірнісний морфологічний аналізатор російської та української мов.
Для вказання цього токенізатора існує параметр з назвою «Tokenizer» в “advSettings”. Якщо значення «stemka» не вказати, то використовується токенізатор «simple» зі стандартної поставки SQLite. Токенайзер «stemka» може приймати на вхід кілька аргументів, які прописуються в параметрі «TokenizerParams»:
- «stem=yes|no» - Включає/виключає морфологічний аналізатор російської та української мов. За замовчуванням значення «yes».
- «lang=uk|ru» - Мова морфологічного аналізатора. За замовчуванням значення «uk», але значення цього параметра контролюється платформою UnityBase при створенні FTS-таблиці сутності і на даний момент не рекомендується використання цього параметра в «TokenizerParams».
Починаючи з версії UB@5.25.26 підтримуються також токенізатори unicode61, porter та trigram. Див. токенізатори FTS3
У випадку використання цих токенізаторів буде використано розширення SQLite FTS5
Важливо:
після зміни значення параметра «Tokenizer» або «TokenizerParams» потрібно ОБОВ'ЯЗКОВО перестворити й потім переіндексувати SQLte БД повнотекстового пошуку, тому що токенізер і його аргументи прописані в заголовку кожної FTS-таблиці. Тобто, БД повнотекстового пошуку буде працювати, але використовувати токенерайзер і аргументи, які були на момент створення цієї БД.
Додавання сутностей до повнотекстового пошуку #
Для додавання сутності до повнотекстового пошуку необхідно в meta файлі сутності налаштувати міксин fts.
myEntity.meta:
"mixins": {
....
"fts": {
"dataProvider": "Mixin",
"scope": "Connection",
"indexedAttributes": ["code", "description"],
"dateAttribute": "docDate"
}
У прикладі вище ми для сутності myEntity:
- використовували з'єднання
ftsDefault(за замовчуванням, оскільки пропущено параметр “connectionName”) для зберігання повнотекстового індексу - вказали необхідність індексувати два атрибути:
codeіdescription - додатково в індекс додали хеш атрибута
docDate, завдяки чому можна виконувати повнотекстовий пошук з урахуванням обмеження за датами
Тепер при будь-яких CRUD операціях з сутністю myEntity повнотекстовий індекс буде оновлюватися синхронно.
Початкове побудова повнотекстового індексу / переіндексація #
У штатному режимі роботи, коли додавання/видалення/модифікація даних сутності проводиться через методи сутності insert/delete/update перебудова повнотекстового індексу проводиться автоматично.
Проте бувають ситуації, коли потрібно перебудувати/побудувати повнотекстовий індекс заново. Наприклад:
- міксин fts додається до сутності, яка вже має дані
- fts був тимчасово відключений на рівні сервера додатків
- база з повнотекстовим індексом втрачена
У такому випадку необхідно скористатися утилітою командного рядка cmd/ftsReindex.
Приклад перебудови всього індексу додатка для autotest:
ubcli -app autotest ftsReindex -c ftsDefault -u admin -p admin
Детальніше див. довідку по команді:
ubcli ftsReindex -help
Налаштування асинхронної реіндексації #
Оновлення (update) одного запису в повнотекстовому індексі - дуже швидка операція (порядку мікросекунд). У зв'язку з цим повнотекстова БД не підтримує довгих транзакцій. У поточній реалізації максимальний час транзакції становить 10 секунд.
Якщо бізнес-логіка додатка працює довго, наприклад після оновлення документа (відповідно - запустилася транзакція в повнотекстовій БД) виконуються ще якісь тривалі обчислення, а в цей момент інший користувач теж зажадає модифікації індексу
- отримаємо помилку
SQLITE_BUSY (5) - «database is locked».
Вихід із ситуації - налаштування fts для запуску в асинхронному режимі. У такому режимі при зміні сутностей з міксином fts не проводиться
миттєве оновлення повнотекстового індексу, але в чергу повідомлень ubq_messages записується команда на оновлення індексу за модифікованим екземпляром.
Безпосередньо оновлення індексу виконується планувальником завдань шляхом періодичного запуску завдання UB.UBQ.FTSReindexFromQueue.
Включаємо асинхронне оновлення повнотексту #
На рівні додатка, в конфігурації (ubConfig.json) додаємо опцію fts.async: true:
"application": {
......
"fts": {
"enabled": true,
"async": true
},
.....
"connections": {
......
}
}
У переліку моделей domainConfigs має бути додана модель UBQ
Налаштовуємо планувальник #
Додаємо нове завдання планувальника для періодичного оновлення індексу, наприклад раз на 10 хвилин
у конфігураційний файл планувальника \Autotest\schedulers\schedulers.json:
{
....,
"fts":{
"enabled": true,
"ownerUser": "admin",
"runcmd": "UB.UBQ.FTSReindexFromQueue",
"useDaysOf": "Month",
"daysOfMonth": [],
"allMonthDays": true,
"lastMonthDay": true,
"daysOfWeek": [],
"timePeriodic": "Periodic",
"timeList": [],
"timePeriodicHour": 0,
"timePeriodicMinute": 10,
"name": "fts"
}
}
Вмикаємо планувальник на рівні додатка:
UB_USE_SCHEDULERS=true в env файлі або явно в конфізі
{
"application": {
"schedulers": {
"enabled": true
}
}
}
Програмне використання повнотекстового пошуку #
Пошук за конкретною сутністю #
Пошук за конкретною сутністю - використовуємо умову match в where:
UB.Repository('myEntity').attrs(["ID", "code"])
.where('', 'match', 'республіка')
.selectAsObject()
.then(UB.logDebug);
З додаванням умов на інші атрибути сутності (у даному прикладі - docDate):
UB.Repository('tst_document').attrs("ID")
.where('', 'match', 'Україна')
.where('docDate', '<', new Date(2015, 02, 13))
.selectAsArray()
.then(UB.logDebug);
Обидва приклади вище виконуються в 2 етапи:
- пошук за повнотекстовим індексом ідентифікаторів записів, що задовольняють умові
match - вибір із сутності записів за знайденими ідентифікаторами з накладенням додаткових умов (якщо вони є)
Безсумнівний плюс такого підходу - можливість вибрати будь-який набір атрибутів сутності, а не тільки ті атрибути, які включені в повнотекстовий індекс, а також - побудова фінальної вибірки з урахуванням обмежень, що накладаються на сутність іншими міксинами, наприклад RLS.
Пошук по всіх сутностях одного індексу #
При підключенні fts в сутностях і вказівці атрибутів для індексування створюється таблиця в файлі повнотекстового
пошуку, яка містить індексовані дані
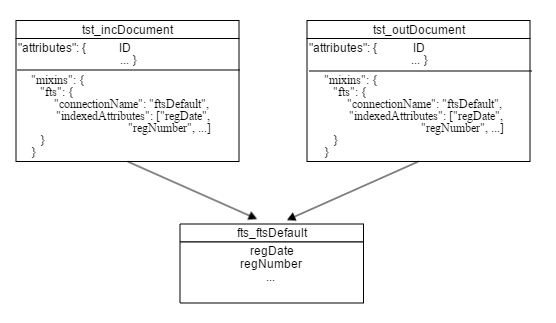
Пошук по всіх сутностях в даному конекшині - використовуємо метод fts_ftsDefault.fts:
$App.connection.run({
entity: "fts_ftsDefault",
method: "fts",
fieldList: ["ID", "entity", "entitydescr", "snippet"],
whereList: {match: {condition: "match", values: {"any": "Україна"}}},
options: {limit: 100, start: 0}
})
.then(function(result){...});
Але також можна вказувати конкретну сутність tst_incDocument, використовуючи метод fts.
UI-елементи повнотекстового пошуку #
Комбобокс із підтримкою повнотекстового пошуку #
Віджет для верхньої панелі #
Віджет повнотекстового пошуку packages/adminui-vue/components/navbarSlotDefault/UNavbarSearchButton.vue для верхнього тулбара дозволяє користувачеві шукати по всіх сутностях обраного коннекшину. На програмному рівні робить запит, аналогічний описаному в «Пошук по всіх сутностях одного індексу»
В результаті отримаємо наступний функціонал
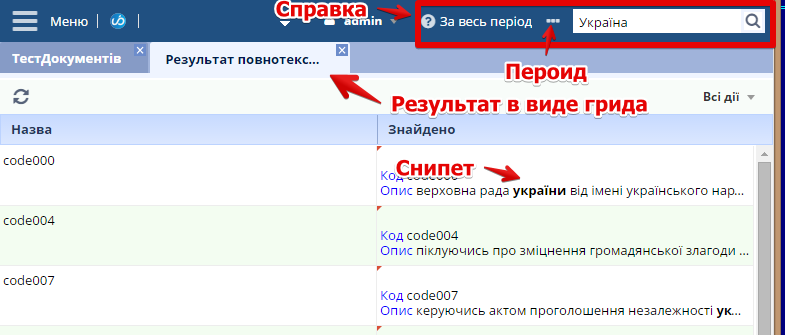
Подвійний клік на рядку грида з результатами пошуку відкриє форму за замовчуванням відповідної сутності.
Див. документацію та приклади використання
Створення власного пошуку на формі #
Приклад створення власного поля пошуку з використанням fts за аналогією з віджетом UB.view.FullTextSearchWidget:
-
Створюємо рядок для введення даних:
var me = this me.textBox = Ext.create('Ext.form.field.Text', { enableKeyEvents: true, fieldLabel: UB.i18n('myFieldLabel'), style: "color: black; border-width: 5px;", fieldStyle: "border-width: 0px;", listeners: { keyup: function(sender, e){ if (e.getKey() === e.ENTER){ me.buttonClick(); } }, scope: me } }); -
якщо необхідно, створюємо кнопку-іконку пошуку:
me.button = Ext.create('Ext.button.Button',{ border: false, margin: 3, padding: 1, style: {backgroundColor: 'white'}, iconCls: 'u-icon-search', handler: me.buttonClick, scope: me }); -
додаємо в потрібне місце на формі:
{ xtype: 'panel', layout: 'hbox', style: { background: "white" }, items: [ me.textBox, me.button ] } -
Використовуємо пошук за всіма сутностями або конкретно вказаною (див.
Пошук за всіма сутностями одного індексу):buttonClick: function () { ... $App.connection.run({ entity: "fts_ftsDefault", method: "fts", fieldList: ["ID", "entity", "entitydescr", "snippet"], whereList: {match: {condition: "match", values: {"any": "Україна"}}}, options: {limit: 100, start: 0} }) .then(function(result){...}); ... }
Попередня фільтрація довідника (автофільтр) #
При передачі на рівні команди showList параметра autoFilter
(приклад ярлика):
{
"cmdType": "showList",
"autoFilter": true,
"cmdData": {
"params": [{
"entity": "tst_document",
"method": "select",
"fieldList": ["favorites.code", "docDate", "code", "description", "fileStoreSimple"]
}]
}
}
для сутностей з міксином fts додається окрема вкладка «Повнотекстовий пошук»:
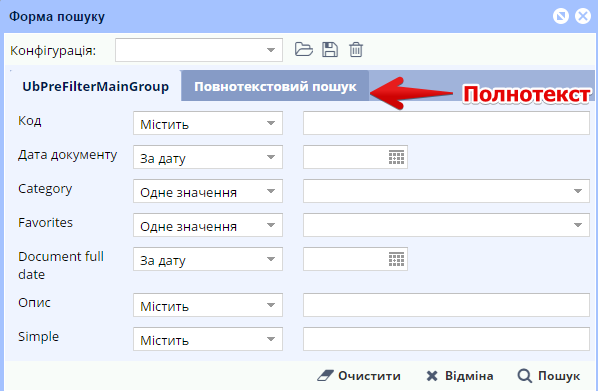
Для грідів, відфільтрованих повнотекстовим пошуком - відповідна індикація:

На програмному рівні формується запит, аналогічний описаному в «Пошук за конкретною сутністю».
Див. додатково документацію з конфігурації автофільтра
Правила побудови запитів #
Службові символи, які беруть участь у побудові запиту #
| Службові символи |
|---|
| * |
| # |
| ( |
| ) |
| [ |
| ] |
Символи-роздільники, пошук за якими не буде здійснюватися #
Символи з таблиці нижче є незначущими для повнотекстового індексу (грубо кажучи - це все одно, що пробіл)
| Символи-роздільники |
|---|
| - |
| , |
| . |
| / |
| \ |
| : |
| { |
| } |
| = |
| + |
| & |
| ^ |
| % |
| $ |
| @ |
| # |
| ! |
| ? |
| ~ |
| ` |
| ' |
| ; |